Die Erschwinglichkeit von Deepseek ist ein Mythos: Die revolutionäre KI kostet tatsächlich 1,6 Milliarden US -Dollar für die Entwicklung
Autor: Ryan
Mar 16,2025

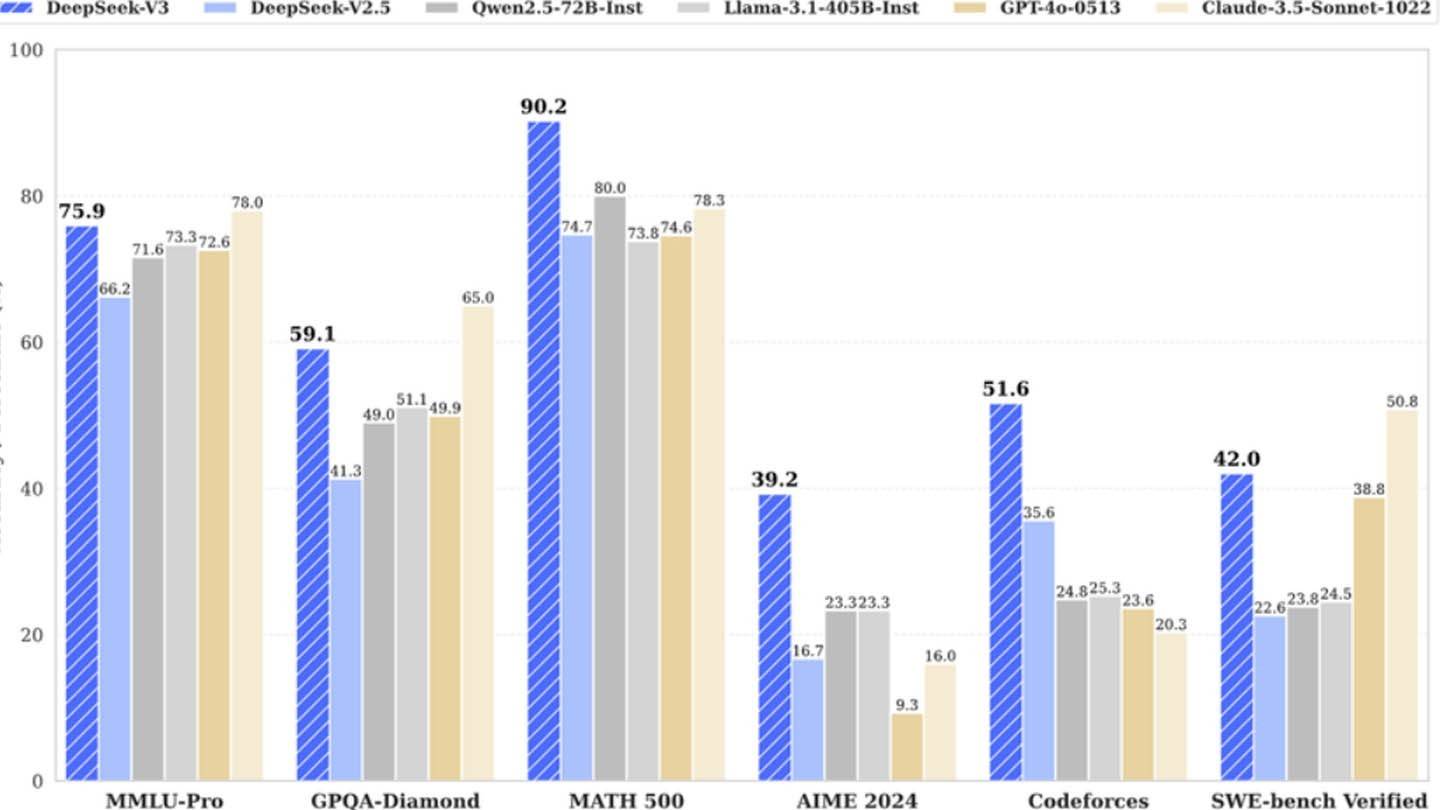
Deepseeks neuer Chatbot bietet eine beeindruckende Einführung: "Hallo, ich wurde erstellt, damit Sie alles fragen und eine Antwort erhalten können, die Sie sogar überraschen könnte." Diese KI, ein Produkt des chinesischen Startups Deepseek, ist schnell zu einem wichtigen Marktspieler geworden und hat sogar zu einem erheblichen Rückgang des NVIDIA -Aktienkurses beigetragen. Der Erfolg beruht auf einer einzigartigen Architektur- und Trainingsmethodik, die mehrere innovative Technologien einbezieht.
Multi-Token-Vorhersage (MTP): Im Gegensatz zur herkömmlichen Wort für Wortvorhersage prognostiziert MTP mehrere Wörter gleichzeitig und analysiert verschiedene Satzkomponenten auf verbesserte Genauigkeit und Effizienz.
Mischung von Experten (MOE): Diese Architektur nutzt mehrere neuronale Netzwerke, um Eingabedaten zu verarbeiten, das KI -Training zu beschleunigen und die Leistung zu steigern. Deepseek V3 verwendet 256 neuronale Netze und aktiviert acht für jede Token -Verarbeitungsaufgabe.
Multi-Head Latent Achtung (MLA): Dieser Mechanismus konzentriert sich auf wichtige Satzelemente und extrahiert wiederholt Schlüsseldetails aus Textfragmenten, um den Informationsverlust zu minimieren und subtile Nuancen zu erfassen.
Deepseek behauptete zunächst eine bemerkenswert niedrige Ausbildungskosten von nur 6 Millionen US -Dollar für sein mächtiges Deekseek V3 -Modell mit nur 2048 GPUs. Die semiianalyse ergab jedoch eine weitaus wesentlichere Infrastruktur: ungefähr 50.000 NVIDIA Hopper -GPUs (einschließlich 10.000 H800, 10.000 H100 und zusätzlicher H20 -GPU), die auf mehrere Rechenzentren verteilt sind. Dies führt zu einer Serverinvestition von rund 1,6 Milliarden US -Dollar und Betriebskosten, die auf 944 Mio. USD geschätzt werden.
Deepseek, eine Tochtergesellschaft des chinesischen Hedgefonds-High-Flyer, besitzt seine Rechenzentren, im Gegensatz zu vielen Startups, die sich auf Cloud-Dienste verlassen. Dieses Eigentum gewährt die vollständige Kontrolle über die Modelloptimierung und eine schnellere Implementierung von Innovationen. Der selbstfinanzierte Status des Unternehmens verbessert die Flexibilität und die Entscheidungsgeschwindigkeit. Darüber hinaus zieht Deepseek Top -Talente an, wobei einige Forscher jährlich über 1,3 Millionen US -Dollar verdienen und hauptsächlich von führenden chinesischen Universitäten rekrutieren.
Während Deepseeks anfängliche Schulungskostenansprüche in Höhe von 6 Millionen US-Dollar unrealistisch erscheint und sich nur für die Nutzung der GPU vor der Training vorliegt und Forschung, Verfeinerung, Datenverarbeitung und Infrastruktur ausgeschlossen hat, hat das Unternehmen immer noch mehr als 500 Millionen US-Dollar in die AI-Entwicklung investiert. Die magere Struktur ermöglicht jedoch eine effiziente Implementierung von Innovationen im Vergleich zu größeren, bürokratischeren Wettbewerbern.
Das Beispiel von Deepseek zeigt ein gut finanziertes unabhängiges KI-Unternehmen, das erfolgreich mit Branchenriesen konkurriert. Während der "revolutionäre Budget" -Anspruch übertrieben ist, ist der Erfolg des Unternehmens unbestreitbar und wird durch erhebliche Investitionen, technische Durchbrüche und ein starkes Team angeheizt. Der Kontrast ist im Vergleich der Schulungskosten stark: Deepseeks R1-Modell kostete 5 Millionen US-Dollar, während Chatgpt-4 100 Millionen US-Dollar kostete und die relative Kosteneffizienz von Deepseek hervorhebt. Sogar angesichts der erheblichen Investitionen bleibt die Kosten von Deepseek weiterhin deutlich niedriger als die Wettbewerber.