A acessibilidade do Deepseek é um mito: a IA revolucionária realmente custou US $ 1,6 bilhão para se desenvolver
Autor: Ryan
Mar 16,2025

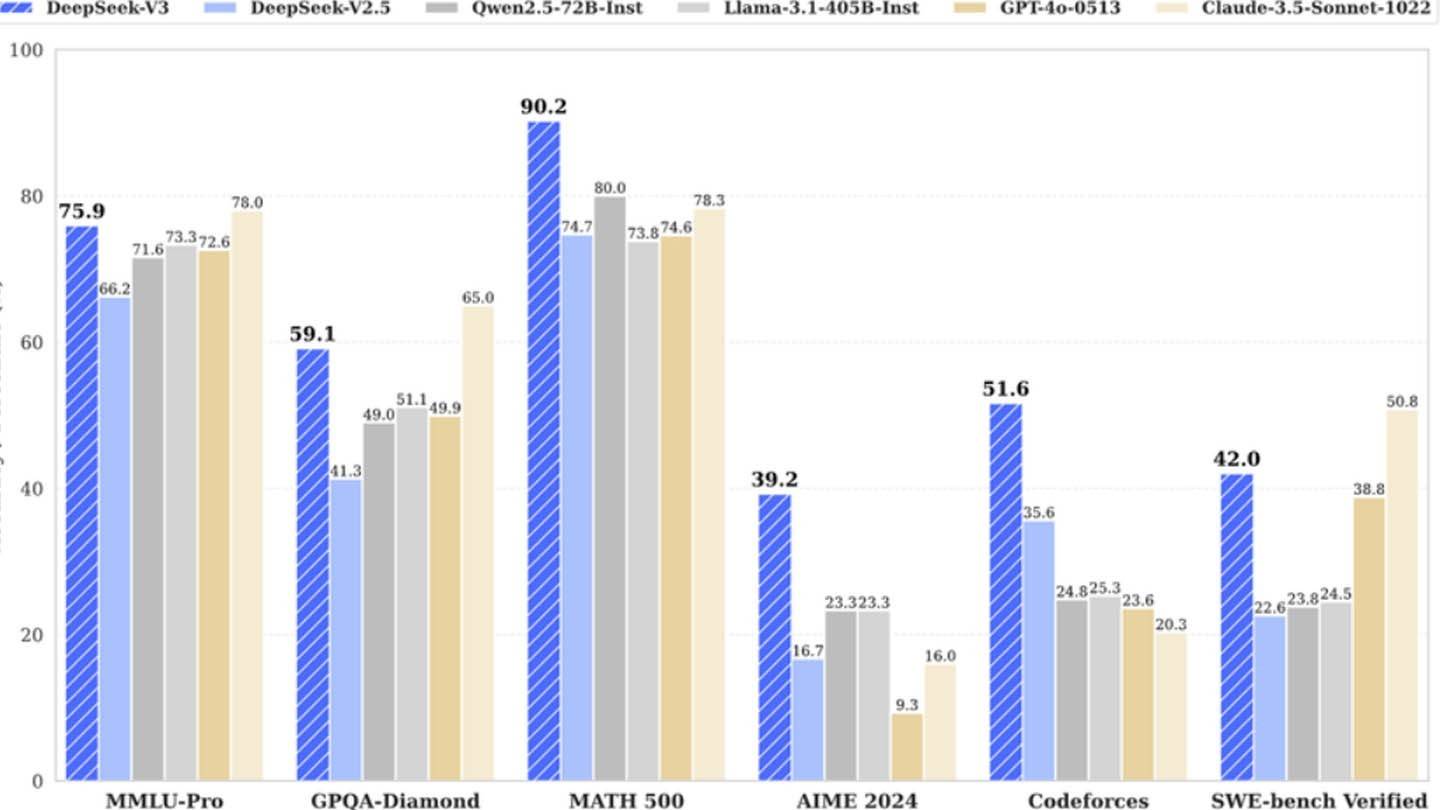
O novo chatbot de Deepseek possui uma introdução impressionante: "Oi, fui criado para que você possa perguntar qualquer coisa e obter uma resposta que possa até surpreendê -lo". Essa IA, um produto da startup chinesa Deepseek, tornou -se rapidamente um dos principais players de mercado, contribuindo para uma queda significativa no preço das ações da Nvidia. Seu sucesso decorre de uma metodologia exclusiva de arquitetura e treinamento que incorpora várias tecnologias inovadoras.
Previsão de vários toques (MTP): Ao contrário da previsão tradicional de palavra por palavra, o MTP prevê várias palavras simultaneamente, analisando vários componentes de frase para maior precisão e eficiência.
Mistura de especialistas (MOE): Esta arquitetura aproveita várias redes neurais para processar dados de entrada, acelerando o treinamento de IA e aumentando o desempenho. O Deepseek V3 utiliza 256 redes neurais, ativando oito para cada tarefa de processamento de token.
Atenção latente de várias cabeças (MLA): Esse mecanismo se concentra nos elementos cruciais da frase, extraindo repetidamente os principais detalhes dos fragmentos de texto para minimizar a perda de informações e capturar nuances sutis.
A Deepseek reivindicou inicialmente um custo de treinamento notavelmente baixo de apenas US $ 6 milhões para seu poderoso modelo Deepseek V3 usando apenas 2048 GPUs. No entanto, a semiânica revelou uma infraestrutura muito mais substancial: aproximadamente 50.000 GPUs NVIDIA Hopper (incluindo 10.000 H800, 10.000 H100 e GPUs H20 adicionais) espalhadas por vários data centers. Isso se traduz em um investimento em servidor de aproximadamente US $ 1,6 bilhão e despesas operacionais estimadas em US $ 944 milhões.
A Deepseek, uma subsidiária do fundo de hedge chinês, possui seus data centers, ao contrário de muitas startups que dependem de serviços em nuvem. Essa propriedade concede controle completo sobre otimização de modelos e implementação mais rápida da inovação. O status autofinanciado da empresa aumenta a flexibilidade e a velocidade de tomada de decisão. Além disso, a Deepseek atrai os melhores talentos, com alguns pesquisadores ganhando mais de US $ 1,3 milhão anualmente, recrutando principalmente das principais universidades chinesas.
Embora a reivindicação inicial de custo de treinamento de US $ 6 milhões da Deepseek pareça irrealista-referindo-se apenas para pré-treinamento de uso da GPU e excluir pesquisas, refinamento, processamento de dados e infraestrutura-a empresa ainda investiu mais de US $ 500 milhões em desenvolvimento de IA. Sua estrutura enxuta, no entanto, permite implementação eficiente de inovação em comparação com concorrentes maiores e mais burocráticos.
O exemplo da Deepseek mostra uma empresa independente de IA bem financiada competindo com sucesso com gigantes do setor. Embora a reivindicação do "orçamento revolucionário" seja exagerada, o sucesso da empresa é inegável, alimentado por investimentos significativos, avanços técnicos e uma equipe forte. O contraste é acidentado ao comparar os custos de treinamento: o modelo R1 da Deepseek custou US $ 5 milhões, enquanto o ChatGPT-4 custou US $ 100 milhões, destacando a eficiência de custos relativa de Deepseek. Mesmo considerando o investimento substancial, o custo da Deepseek permanece significativamente menor que seus concorrentes.